Menghitung jumlah sampel
Akhir-akhir ini, di dunia maya Indonesia terdapat perbincangan mengenai quick count dan ukuran sampel yang dipakai. Hasil quick count dari lembaga penelitian yang berbeda menunjukkan persentase berbeda. Ada lembaga membuka metodologi yang digunakan dan dapat diunduh di website mereka, contoh Saiful Mujani Research Center. Beberapa tidak menunjukkan metodologinya kepada publik.
Tulisan kali ini ingin menulis tentang bagaimana cara menentukan ukuran sampel. Ada beberapa rumus matematika yang bisa dipakai untuk mengukur sampel. Aku ingin menuliskan dua rumus yang lagi hangat di media sosial dan satu rumus dari kuliah “Multivariate Statistic” yang sedang kujalani.
***
Rumus Pertama:
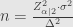
Penjelasan:
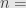
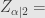
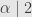
Angka 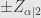
Pada tingkat kepercayaan 95%, 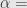
Pada tingkat kepercayaan 99%,
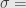
Berhubung adanya asumsi bahwa proses pada quick count itu hanya tentang memilih calon X atau tidak memilih calon X, simpangan baku maksimum adalah 0,5. Ini sesuai Bernoulli Process dan Binomial Distribution.
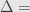
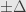
Rumus di atas adalah penurunan dari rumus menghitung margin of error, tanpa Finite Error Correction (FEC):
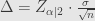
Contoh 1.1:
Kita menginginkan quick count yang memiliki tingkat kepercayaan 95% (
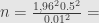
Jadi sampel yang harus diambil ada 9604.
Contoh 1.2:
Bagaimana kalau tingkat kepercayaan yang diinginkan 99% dan margin of error sama?
Dengan rumus yang sama, diperoleh ukuran sampel
Rumus pertama di atas untuk menghitung jumlah sampel bisa dibaca di posting berikut
- Pedoman quick-count dan pengawasan Pemilu, dari National Democratic Institute (NDI):
http://www.ndi.org/files/1417_elect_quickcounthdbk_0.pdf - Wikipedia, tentang penentuan ukuran sampel (wiki: en,de) dan rentang kesalahan/margin of error (wiki: en,id)
- Tulisan Sapto Condro, “Pemilu Indonesia: Survei, Quick Count dan Exit Polls“
- Tulisan Sapto Condro, “Semua pria sama saja“, tentang dunia pencarian jodoh dan statistika.
Asumsi pada rumus pertama adalah galat yang diperhitungkan adalah hanya type I error (wiki: en,de), yang berhubungan dengan tingkat dan selang kepercayaan. Berhubung survei tidak memiliki variabel kontrol yang bisa dijadikan hipotesis nol, type II error (wiki: de) tidak bisa dihitung dan power analysis tidak bisa dilakukan (wiki: en,de).
***
Rumus Kedua:
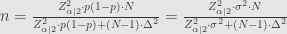
Penjelasan:
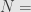
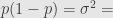
Entropi maksimum tercapai ketika p = 0,5. Jadi margin of error yang paling besar tercapai ketika p = 0,5, jadi asumsikan begitu, sehingga
Rumus di atas adalah penurunan dari rumus menghitung margin of error, dengan Finite Error Correction (FEC):
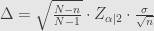
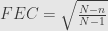
Contoh 2.1:
Kita menginginkan quick count yang memiliki tingkat kepercayaan 95% (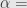
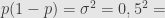

Ternyata hasil rumus kedua mirip dengan rumus pertama, yaitu ukuran sampelnya 9604.
Contoh 2.2:
Bagaimana kalau populasi penduduk hanya 1 juta orang?
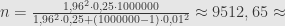
Ukuran sampel menjadi 9513.
Jadi dengan koreksi galat populasi berhingga (finite error correction), kita tidak perlu mengambil 9604 sampel, tetapi cukup 9513 sampel saja. Bedanya dikit banget, yah?
Rumus kedua di atas untuk menghitung jumlah sampel bisa dibaca di posting berikut
- Pedoman quick-count dan pengawasan Pemilu, dari National Democratic Institute (NDI):
http://www.ndi.org/files/1417_elect_quickcounthdbk_0.pdf
(sudah disebutkan di atas) - Wikipedia, tentang penentuan ukuran sampel dan rentang kesalahan/margin of error yang telah disebutkan di atas.
- Tulisan Ratih Nokowati, “Quick Count Pileg 2014 Konspirasi Media?“, tentang pengalamannya bekerja 3 tahun di lembaga survei.
Asumsi yang dipakai pada rumus kedua dan pertama itu sama, yaitu hanya memperhitungkan type I error tetapi tidak memasukkan type II error.
***
Hubungan antara rumus pertama dan kedua
Rumus kedua jika diturunkan lebih lanjut akan menjadi
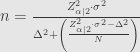
Dan bisa dibandingkan dengan rumus pertama
Terlihatlah bahwa finite error correction (FEC), menimbulkan efek 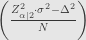
Jadi sesuai prinsip parsimoni atau Occam’s Razor, pilih rumus pertama yang lebih sederhana. Jumlah sampel menggunakan rumus kedua tidak jauh berbeda dengan rumus pertama.
***
Rumus Ketiga:
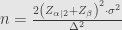
Penjelasan:

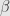
Pada statistical power sebesar 0,90, nilai 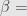
Diasumsikan sebesar 0,5.
Contoh 3.1:
Pimpinan suatu parpol menargetkan Pemilu ini akan mendapat 27%. Diinginkan suatu survei dengan margin of error 1% dan tingkat kepercayaan 95% serta power sebesar 90%. Berapa ukuran sampel yang dibutuhkan?
untuk tingkat kepercayaan 95%, yaitu
untuk power 90%, yaitu

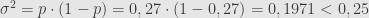
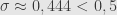
Jika tidak menggunakan asumsi simpangan baku 0,5, maka menghitung ukuran sampel sebagai berikut.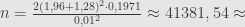
Jika menggunakan asumsi simpangan baku 0,5, maka ukuran sampel dihitung sebagai berikut.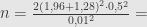
Jadi untuk memperkirakan apakah target pimpinan parpol tersebut itu akan tercapai atau tidak, dibutuhkan suatu survei dengan ukuran sampel sebesar 41.382 atau 52.488, tergantung asumsi.
Pada rumus pertama dan kedua, ukuran sampel yang dibutuhkan tidak lebih dari 9604, sedangkan pada rumus ketiga, ukuran sampel mencapai 50 ribu. Ini menunjukkan bahwa memasukkan power analysis atau type II error ke dalam perhitungan, bisa menyebabkan ukuran sampel membesar. Sesuai prinsip parsimoni atau Occam’s Razor, pilihlah metode dengan asumsi yang paling ringkas dan sederhana. Jadi rumus pertama saja yang sebaiknya dipakai dalam survei politik dan hitung cepat dalam pemilu, juga dengan asumsi simpangan baku maksimum 0,5. Ini juga sudah dipakai dalam quick count dan survei politik yang dilakukan oleh National Democratic Institute (NDI) di berbagai negara.
Rumus ketiga ini bisa dibaca dari buku berikut
- Brian S. Everitt, 2010, Multivariable Modeling and Multivariate Analysis for the Behavioral Sciences. Chapter 1, pp 15. CRC Press, Taylor & Francis Group. ISBN 978-1-4398-0769-9
***
Jadi setelah membaca penjelasan tiga rumus untuk menghitung ukuran sampel dalam survei politik maupun exit polls dan hitung cepat (quick count) pemilu, kita bisa belajar mengetahui apakah kata-kata seorang politisi itu sekedar basa-basi politik atau memiliki argumen ilmiah yang valid. Dengan matematika, terutama ilmu probabilitas dan statistika, kita bisa memperkirakan kondisi sosial politik suatu masyarakat. Hal ini bisa membantu politisi dalam menyusun langkah strategis selanjutnya dalam berpolitik. Karena politik itu tidak hanya basa-basi. Hal ini juga bisa membantu masyarakat awam untuk lekas tahu kira-kira seperti apa hasil pemilu, pilpres atau pilkada. Jadi rakyat tahu akan menghadapi pemimpin seperti apa selama sekian tahun ke depan.
Dalam politik, bukan hanya persamaan matematika yang berlaku. Jadinya belajar survei politik itu bukan hanya rumus matematika, namun juga dampak politik yang terjadi pada elit maupun bagi rakyat kebanyakan. Posting ini hanya menjelaskan matematika di balik quick count dan survei sosial politik sejenisnya. Jadi ada kemungkinan “mathematically correct, but politically incorrect”. Jika tersinggung dengan tulisan ini, salahkan matematikawan yang bikin rumus di atas.
Bremen, 26 Agustus 2014
P.S. Tulisan ini seharusnya selesai di Oldenburg tanggal 14 Juli 2014, tapi karena aku menunda-nunda jadinya baru selesai hari ini.
Pemilu Indonesia: Survei, Quick Count dan Exit Polls
Hari ini hari pemilihan anggota legislatif dalam rangkaian Pemilu Indonesia tahun 2014. Pada tahun 2004, banyak pimpinan partai politik yang membuat klaim angkat memperoleh sekian persen suara atau sekian persen kursi. Sebetulnyaklaim tersebut dapat dibuktikan dengan uji hipotesis berdasarkan statistik. Akan tetapi, saat itu, lembaga survei politik belum banyak. Tahun 2009, kemampuan statistika dipakai oleh beberapa lembaga survei untuk membuat “quick count” atau hitung cepat dan “exit polls” untuk memperkirakan hasil Pemilu.
Pada saat itu, sejumlah pimpinan partai politik begitu gagap dengan penggunaan sains dalam politik, dalam hal ini matematika atau statistika. Sebagian mengeluarkan pernyataan bahwa survei ini survei bayaran partai lawan atau data direkayasa. Sebagian lain membuat survei yang tidak ilmiah, yang bertujuan menyenangkan pimpinan parpol tapi sama sekali tidak bisa menggambarkan opini publik. Sebagian pemakai internet membuat internet polling di website dan blog.
Posting saya kali ini adalah tentang penjelasan bagaimana suatu survei ilmiah dibuat. Juga ada penjelasan apa itu “quick count” dan “exit polls”. Pada survei ilmiah, harus ada penjelasan mengenai tingkat kepercayaan, batas kesalahan dan jumlah sampel, serta bagaimana caranya survei atau polling dilakukan.
***
Istilah-istilah yang dipakai dalam Pemilu Indonesia dari 2004 hingga 2014:
- Survei (politik) adalah suatu jajak pendapat pada sejumlah orang sebagai untuk memperkirakan opini publik dari suatu populasi. Pada survei ilmiah, pengambilan sampel dari 2000 orang secara acak terkendali bisa menggambarkan opini publik dari populasi 100 juta orang. (wiki tentang survey: en,de,id)
- Survei menjelang pemilihan adalah survei yang dilakukan sebelum pemilihan umum atau pemilihan lain seperti pilkada, pilgub, dll. Survei menjelang pemilihan biasa dilakukan untuk menghitung elektabilitas suatu partai atau orang peserta pemilihan. Dari wiki Pemilu 2014, sejumlah survei ini bisa dilihat hasilnya.
- Hasil penghitungan suara sementara adalah hasil penghitungan suara yang dilakukan KPU dan panitia pemilihan, dari tingkat TPS, kecamatan, kota/kabupaten/provinsi, hingga pusat. Pada tahun 2004 dan 2009, ada IT KPU yang menyajikan hasil penghitungan suara sementara di website. Ini bukan survei dan bukan polling, walau secara matematis bisa saja diperlakukan sebagai suatu survei.
- Quick Count atau Hitung Cepat adalah metode pengambilan sampel dari beberapa tempat pemungutan suara (TPS) untuk memperkirakan hasil Pemilu. Yang menjadi sampel pada quick count adalah hasil TPS, bukan orang. Jadi dari sebagian TPS, misalnya 2000 TPS, kita bisa memprediksi hasil dari seluruh populasi, yaitu 550 ribu TPS atau lebih.
- Exit Polls adalah jajak pendapat dari orang-orang yang telah selesai mencoblos di TPS. Yang menjadi sampel pada exit polls adalah orang. Pada exit polls, selain pertanyaan apa partai yang dipilih, peserta polling juga bisa ditanya mengenai identitasnya (agama, umur, tingkat pendidikan, dll) dan opini mengenai pemilu, seperti apa harapan ke depan, siapa presiden yang akan dipilih, pemilu sebelumnya memilih apa, dll. Dari exit polls, sampel 2000 orang bisa dipakai menggambarkan opini publik dari populasi 100 juta orang.
- Internet Polling adalah pengambilan sampel yang dibuat oleh website atau blog. Ini bukan survei ilmiah karena pengambilan sampel tidak bisa terkendali: apakah satu orang memilih lebih dari satu kali, bagaimana penyebaran geografis peserta polling, dll. Internet polling cukup marak pada Pemilu 2004 dan 2009. Saat itu berdasarkan internet polling, PKS mendapat lebih dari 40% suara.
- SMS Polling adalah pengambilan sampel menggunakan SMS. Ini juga bukan survei ilmiah, dengan alasan yang sama dengan internet polling.
***
Apa itu survei ilmiah? Suatu survei politik itu ilmiah jika pengambilan sampel dilakukan secara acak dan batas-batas yang jelas (terkendali). Acak (random) itu maksudnya tidak ada pola. tiada hubungan kausalitas dan tiada hubungan koherensi (wiki: en,de). Contoh hal-hal yang tidak acak, adalah pengambilan sampel dilakukan hanya pada golongan tertentu atau hanya pada daerah tertentu. Polling di laman internet dan via SMS bisa menyebabkan hal-hal yang tidak acak karena pesertanya bisa saja hanya dari golongan tertentu. Batas yang jelas (terkendali) pada suatu survei yang dimaksud adalah seperti ini
- Berapa jumlah sampelnya? Mengapa?
- Bagaimana cara pengambilan sampel? Mengapa?
- Rentang waktu kapan pengambilan sampel diambil.
- Berapa jumlah sampel di daerah ini dan di daerah itu? Mengapa?
- Berapa jumlah sampel pria dan yang wanita? Mengapa?
Pada pengambilan sampel secara acak sederhana (simple random sampling, wiki: en), kita bisa mengambil sampel sejumlah tertentu misalnya 2000. Lalu kita bisa menghitung rata-rata atau proporsi suara pilihan politik. Pelaku survei tinggal bertanya kepada 2000 orang yang ditemui secara acak. Akan tetapi cara ini menyimpan kelemahan. Indonesia memiliki kondisi geografis tertentu dan penyebaran penduduk khas. Jika metode acak sederhana yang dipakai, penyurvei bisa bertanya secara acak di daerah ini namun lupa bertanya di daerah lain. Akibatnya hasil survei belum tentu menggambarkan opini publik. Cara lain adalah dengan menggunakan pengambilan sampel secara acak berjenjang (stratified random sampling, wiki: en,de). Contoh:
- Pada pengambilan sampel, di provinsi ini sampel diambil sekian dan di tempat lain berbeda, sesuai proporsi jumlah penduduk. Begitu pula proporsi di kota ini dan di kabupaten itu.
- Proporsi kota dan desa juga diperhatikan, misalnya sampel diambil di 60% desa dan 40% kelurahan (di kota) berdasarkan proporsi penduduk.
- Proporsi pria dan wanita juga diperhatikan, misalnya sample pria dan sampel wanita harus sama (50:50).
Dengan metode pengambilan sampel secara acak berjenjang ini, opini publik bisa digambarkan menurut distribusi wilayah, gender, dan geografis.
***
Berapa jumlah sampel yang harus diambil? Jumlah sampel yang diambil itu tergantung seberapa akurat kita ingin memperkirakan seluruh populasi. Prinsipnya ada dua:
- Semakin banyak sampel, semakin akurat
- Semakin banyak sampel, semakin mahal biaya survei
Menurut statistika, jumlah sampel itu tergantung seberapa besar batas kesalahan (margin of error) dan tingkat kepercayaan (confidence level) yang kita tetapkan. Rumusnya ada di bawah.
***
Apa itu batas kesalahan? Batas kesalahan atau margin of error adalah rentang kesalahan pada hasil suatu pengambilan sampel (wiki: en,id). Misalnya pada survei politik, ada tulisan margin of error 2%, sedangkan PDI-P mendapat 19%, Golkar 14%, PKS 5% , dll. Itu artinya PDI-P suaranya bisa meleset plus-minus 2%, sehingga suara PDI-P berkisar 17 hingga 21%. Sedangkan Golkar antara 12 hingga 16%. Lalu PKS antara 3 hingga 7%. Hubungan antara batas kesalahan dengan jumlah sampel akan dijelaskan pada rumus di bawah.
***
Apa itu tingkat kepercayaan dan selang kepercayaan? Tingkat kepercayaan (confidence level) dan selang kepercayaan (confidence interval) saling berhubungan. Hal ini bisa dijelaskan dengan gambar Distribusi Gaussian (dari website National Curve Bank) berikut ini.

Distribusi Gaussian
Pada distribusi normal atau Gaussian, terdapat kurva berbentuk bel seperti pada gambar. Di situ terdapat angka rata-rata yaitu 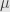
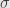
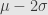

Di sini selang kepercayaan (confidence interval) menunjukkan seberapa jauh hasil sampling boleh menyimpang untuk tetap dipercaya. Tingkat kepercayaan (confidence level) menunjukkan probabilitas atau kemungkinan suatu hasil sampling berada pada selang kepercayaan. Silahkan baca buku probabilistika dan statistika dasar untuk penjelasan yang lebih baik dan kalau malas silahkan baca wiki: en,de,id.
Untuk meningkatkan tingkat kepercayaan, selang kepercayaan harus diperlebar. Berarti hasilnya harus semakin menyimpang dari angka rata-rata, dong? Berarti makin besar saja batas kesalahannya, dong? Ya, betul, akan tetapi jika simpangan
***
Rumus ini, adalah rumus mencari batas kesalahan (margin of error), pada survei.
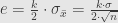
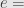

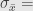


Dari rumus di atas, dapat dicari hubungan antara berapa batas kesalahan yang dimaklumi dan berapa jumlah sampel yang diinginkan. Semakin besar jumlah sampel, maka semakin kecil kesalahannya. Selain itu, tingkat kepercayaan (confidence level) dan selang kepercayaan (confidence interval) berhubungan dengan besarnya 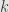
setara dengan selang kepercayaan
dan tingkat kepercayaan 68,26%
setara dengan tingkat kepercayaan 95% dan selang kepercayaan
setara dengan selang kepercayaan
dan tingkat kepercayaan 95,44%
setara dengan tingkat kepercayaan 99% dan selang kepercayaan
setara dengan selang kepercayaan
dan tingkat kepercayaan 99,74%
***
Contoh pertama:
Hasil exit polls dari Center for Strategic and International Studies (CSIS) dan Cyrus Network, 9 April 2014 (dari berita Antara).
Jumlah sampel 8000 orang. Berapa batas kesalahannya (margin of error)?
Jika tingkat kepercayaan 95%, maka selang kepercayaan 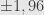
Batas kesalahannya adalah 0,011 = 1,1%.
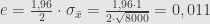
Jika tingkat kepercayaan 99%, maka selang kepercayaan 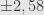
Batas kesalahannya adalah 0,0144 = 1,44%.
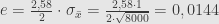
Margin of error yang kecil, tidak lebih dari 1,5%. Lumayan akurat.
***
Contoh kedua:
Hasil quick count dari Jaringan Suara Indonesia (JSI), 9 April 2014 (dari berita KOMPAS).
Jumlah sampel 2000 TPS. Berapa batas kesalahannya (margin of error)?
Jika tingkat kepercayaan 95%, maka selang kepercayaan
Batas kesalahannya adalah 0,022 = 2,2%.
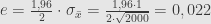
Jika tingkat kepercayaan 99%, maka selang kepercayaan
Batas kesalahannya adalah 0,029 = 2,9%.
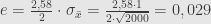
Margin of error di bawah 3%.
***
Contoh ketiga:
Joko ingin membuka usaha survei politik. Dia ingin melakukan survei secara akurat terpercaya. Dia berpikir tingkat kepercayaan 95% dan kalau bisa batas kesalahannya 1% saja. Berapa sampel minimumnya?
Jika tingkat kepercayaan 95%, maka selang kepercayaan
maka

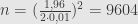
Jadi jumlah sampel yang harus diambil adalah 9604.
Wah, banyak sekali. Joko pun bingung bagaimana menggaji orang buat survei untuk seluruh Indonesia. Biaya perjalanan mereka juga besar. Joko pun berpikir bagaimana kalau batas kesalahannya jadi 3% saja, jadi jumlah sampel cukup 2000 saja.
***
Begitulah hubungan antara jumlah sampel dan batas kesalahan (margin of error) pada suatu survei ilmiah. Jadi pada survei menjelang Pemilu, “exit polls” maupun “quick count”, kita sebagai pembaca atau penonton berita harus kritis dengan bertanya berapa jumlah sampel, batas kesalahan, dan tingkat kepercayaan. Tentu saja kita harus kritis untuk mengetahui bagaimana juga survei dilakukan, misalnya stratified random sampling (acak berjenjang) atau tidak. Kapan survei dilakukan juga perlu diketahui.
Nah, kalau ada pimpinan partai yang membuat klaim partainya akan memperoleh sekian suara atau sekian kursi, akan tetapi hasil beberapa survei ilmiah tidak menunjukkan hasil sesuai kata-kata pimpinan parpol, itu artinya orang ini tidak memiliki argumentasi ilmiah.
Begitu pula, jika ada organisasi jadi-jadian yang biasanya dibentuk oleh suatu partai politik, membuat suatu survei. Akan tetapi dia tidak mencantumkan jumlah sampel, batas kesalahan (margin of error), tingkat kepercayaan, serta bagaimana dan kapan survei diadakan. Itu artinya survei ini ngawur atau tidak ilmiah.
Kalau ada orang yang bilang survei ini rekayasa parpol atau survei itu survei bayaran, kita juga harus kritis. Sekarang ada 56 lembaga survei yang tercatat oleh KPU. Jadi lihat-lihat saja hasil survei dari 56 lembaga tersebut kemudian bandingkan. Serta di wikipedia juga sudah ada yang merangkum survei-survei yang telah dilakukan selama ini. Jangan hanya karena kita tidak suka dengan hasil suatu survei, kita menganggap survei ini ngawur.
Ada 56 lembaga survei untuk Pemilu. http://t.co/c0Ad8GBLvP
— iscab.saptocondro (@saptocondro) April 2, 2014
***
Posting ini adalah posting tentang penggunaan statistika dalam dunia politik. Posting serupa dalam dunia perjodohan, bisa dibaca pada “Semua pria sama saja“.
Oldenburg, 9 April 2014
Ignatius Sapto Condro Atmawan Bisawarna (iscab)
rank
twiscab
 Darah Juang, Dr. Dro!
Darah Juang, Dr. Dro!- An error has occurred; the feed is probably down. Try again later.
- Brain Robot Research
- EEG electrode placement summary, April 2015
- Bandung Brain-Computer Interface on Indonesia Morning Show, Net TV, June 2014
- EEG electrode placement summary, August 2014
- Bandung Brain Computer Interface: Bionic Arm 2014
- CMS and DRL
- How seriously is Indonesia doing research on Brain-Computer Interface?
- SSVEP electrode position, on my head
- Ethical Questions on Brain Computer Interface, by Paul Root Wolpe
- Bandung Brain Computer Interface
- Standard 10-20 system EEG & me
- The Church of Robotics
- technologeek gaptek
- info beasiswa / scholarship
- An error has occurred; the feed is probably down. Try again later.
- info lowongan kerja / job vacancy
- An error has occurred; the feed is probably down. Try again later.
Badge

social badge



Recent Comments
- iscab.saptocondro
- iscablr
- Senja di Kanal Wolfsburg
- Ketika kita siap BERAKtivitas. Lalu ada kehendak usus besar,...
- Internet 5G ala kampung di Jerman. kbps bukan Mbps. Di...
- Volkswagen di hari Minggu. Volkswagen on a Sunday. Volkswagen...
- Web 1.0, Web 2.0, Web 3.0 Jejaring punya versi #web #123...
- Kuliah yang rajin dan tekun kalau sudah diterima di perguruan...
- 2 Belimbing Malaysia seharga 5 EUR total. #belimbing #malaysia...
- Suasana matahari terbenam di musim semi. Sunset in Spring....
- Sahara Sand & Sunset Scattering Pasir dari Sahara &...
- Nasi Anonim, karena belum sempat memberi nama untuk makanan...
- miliscab
- An error has occurred; the feed is probably down. Try again later.
