Menghitung jumlah sampel
Akhir-akhir ini, di dunia maya Indonesia terdapat perbincangan mengenai quick count dan ukuran sampel yang dipakai. Hasil quick count dari lembaga penelitian yang berbeda menunjukkan persentase berbeda. Ada lembaga membuka metodologi yang digunakan dan dapat diunduh di website mereka, contoh Saiful Mujani Research Center. Beberapa tidak menunjukkan metodologinya kepada publik.
Tulisan kali ini ingin menulis tentang bagaimana cara menentukan ukuran sampel. Ada beberapa rumus matematika yang bisa dipakai untuk mengukur sampel. Aku ingin menuliskan dua rumus yang lagi hangat di media sosial dan satu rumus dari kuliah “Multivariate Statistic” yang sedang kujalani.
***
Rumus Pertama:
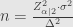
Penjelasan:
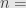
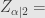
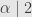
Angka 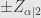
Pada tingkat kepercayaan 95%, 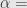
Pada tingkat kepercayaan 99%,
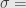
Berhubung adanya asumsi bahwa proses pada quick count itu hanya tentang memilih calon X atau tidak memilih calon X, simpangan baku maksimum adalah 0,5. Ini sesuai Bernoulli Process dan Binomial Distribution.
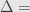
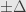
Rumus di atas adalah penurunan dari rumus menghitung margin of error, tanpa Finite Error Correction (FEC):
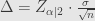
Contoh 1.1:
Kita menginginkan quick count yang memiliki tingkat kepercayaan 95% (
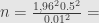
Jadi sampel yang harus diambil ada 9604.
Contoh 1.2:
Bagaimana kalau tingkat kepercayaan yang diinginkan 99% dan margin of error sama?
Dengan rumus yang sama, diperoleh ukuran sampel
Rumus pertama di atas untuk menghitung jumlah sampel bisa dibaca di posting berikut
- Pedoman quick-count dan pengawasan Pemilu, dari National Democratic Institute (NDI):
http://www.ndi.org/files/1417_elect_quickcounthdbk_0.pdf - Wikipedia, tentang penentuan ukuran sampel (wiki: en,de) dan rentang kesalahan/margin of error (wiki: en,id)
- Tulisan Sapto Condro, “Pemilu Indonesia: Survei, Quick Count dan Exit Polls“
- Tulisan Sapto Condro, “Semua pria sama saja“, tentang dunia pencarian jodoh dan statistika.
Asumsi pada rumus pertama adalah galat yang diperhitungkan adalah hanya type I error (wiki: en,de), yang berhubungan dengan tingkat dan selang kepercayaan. Berhubung survei tidak memiliki variabel kontrol yang bisa dijadikan hipotesis nol, type II error (wiki: de) tidak bisa dihitung dan power analysis tidak bisa dilakukan (wiki: en,de).
***
Rumus Kedua:
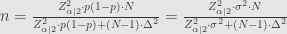
Penjelasan:
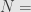
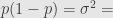
Entropi maksimum tercapai ketika p = 0,5. Jadi margin of error yang paling besar tercapai ketika p = 0,5, jadi asumsikan begitu, sehingga
Rumus di atas adalah penurunan dari rumus menghitung margin of error, dengan Finite Error Correction (FEC):
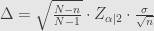
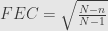
Contoh 2.1:
Kita menginginkan quick count yang memiliki tingkat kepercayaan 95% (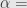
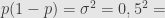

Ternyata hasil rumus kedua mirip dengan rumus pertama, yaitu ukuran sampelnya 9604.
Contoh 2.2:
Bagaimana kalau populasi penduduk hanya 1 juta orang?
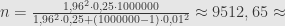
Ukuran sampel menjadi 9513.
Jadi dengan koreksi galat populasi berhingga (finite error correction), kita tidak perlu mengambil 9604 sampel, tetapi cukup 9513 sampel saja. Bedanya dikit banget, yah?
Rumus kedua di atas untuk menghitung jumlah sampel bisa dibaca di posting berikut
- Pedoman quick-count dan pengawasan Pemilu, dari National Democratic Institute (NDI):
http://www.ndi.org/files/1417_elect_quickcounthdbk_0.pdf
(sudah disebutkan di atas) - Wikipedia, tentang penentuan ukuran sampel dan rentang kesalahan/margin of error yang telah disebutkan di atas.
- Tulisan Ratih Nokowati, “Quick Count Pileg 2014 Konspirasi Media?“, tentang pengalamannya bekerja 3 tahun di lembaga survei.
Asumsi yang dipakai pada rumus kedua dan pertama itu sama, yaitu hanya memperhitungkan type I error tetapi tidak memasukkan type II error.
***
Hubungan antara rumus pertama dan kedua
Rumus kedua jika diturunkan lebih lanjut akan menjadi
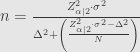
Dan bisa dibandingkan dengan rumus pertama
Terlihatlah bahwa finite error correction (FEC), menimbulkan efek 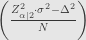
Jadi sesuai prinsip parsimoni atau Occam’s Razor, pilih rumus pertama yang lebih sederhana. Jumlah sampel menggunakan rumus kedua tidak jauh berbeda dengan rumus pertama.
***
Rumus Ketiga:
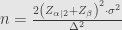
Penjelasan:

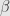
Pada statistical power sebesar 0,90, nilai 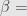
Diasumsikan sebesar 0,5.
Contoh 3.1:
Pimpinan suatu parpol menargetkan Pemilu ini akan mendapat 27%. Diinginkan suatu survei dengan margin of error 1% dan tingkat kepercayaan 95% serta power sebesar 90%. Berapa ukuran sampel yang dibutuhkan?
untuk tingkat kepercayaan 95%, yaitu
untuk power 90%, yaitu

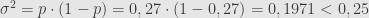
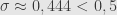
Jika tidak menggunakan asumsi simpangan baku 0,5, maka menghitung ukuran sampel sebagai berikut.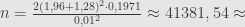
Jika menggunakan asumsi simpangan baku 0,5, maka ukuran sampel dihitung sebagai berikut.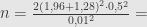
Jadi untuk memperkirakan apakah target pimpinan parpol tersebut itu akan tercapai atau tidak, dibutuhkan suatu survei dengan ukuran sampel sebesar 41.382 atau 52.488, tergantung asumsi.
Pada rumus pertama dan kedua, ukuran sampel yang dibutuhkan tidak lebih dari 9604, sedangkan pada rumus ketiga, ukuran sampel mencapai 50 ribu. Ini menunjukkan bahwa memasukkan power analysis atau type II error ke dalam perhitungan, bisa menyebabkan ukuran sampel membesar. Sesuai prinsip parsimoni atau Occam’s Razor, pilihlah metode dengan asumsi yang paling ringkas dan sederhana. Jadi rumus pertama saja yang sebaiknya dipakai dalam survei politik dan hitung cepat dalam pemilu, juga dengan asumsi simpangan baku maksimum 0,5. Ini juga sudah dipakai dalam quick count dan survei politik yang dilakukan oleh National Democratic Institute (NDI) di berbagai negara.
Rumus ketiga ini bisa dibaca dari buku berikut
- Brian S. Everitt, 2010, Multivariable Modeling and Multivariate Analysis for the Behavioral Sciences. Chapter 1, pp 15. CRC Press, Taylor & Francis Group. ISBN 978-1-4398-0769-9
***
Jadi setelah membaca penjelasan tiga rumus untuk menghitung ukuran sampel dalam survei politik maupun exit polls dan hitung cepat (quick count) pemilu, kita bisa belajar mengetahui apakah kata-kata seorang politisi itu sekedar basa-basi politik atau memiliki argumen ilmiah yang valid. Dengan matematika, terutama ilmu probabilitas dan statistika, kita bisa memperkirakan kondisi sosial politik suatu masyarakat. Hal ini bisa membantu politisi dalam menyusun langkah strategis selanjutnya dalam berpolitik. Karena politik itu tidak hanya basa-basi. Hal ini juga bisa membantu masyarakat awam untuk lekas tahu kira-kira seperti apa hasil pemilu, pilpres atau pilkada. Jadi rakyat tahu akan menghadapi pemimpin seperti apa selama sekian tahun ke depan.
Dalam politik, bukan hanya persamaan matematika yang berlaku. Jadinya belajar survei politik itu bukan hanya rumus matematika, namun juga dampak politik yang terjadi pada elit maupun bagi rakyat kebanyakan. Posting ini hanya menjelaskan matematika di balik quick count dan survei sosial politik sejenisnya. Jadi ada kemungkinan “mathematically correct, but politically incorrect”. Jika tersinggung dengan tulisan ini, salahkan matematikawan yang bikin rumus di atas.
Bremen, 26 Agustus 2014
P.S. Tulisan ini seharusnya selesai di Oldenburg tanggal 14 Juli 2014, tapi karena aku menunda-nunda jadinya baru selesai hari ini.
Pemilu Indonesia: Survei, Quick Count dan Exit Polls
Hari ini hari pemilihan anggota legislatif dalam rangkaian Pemilu Indonesia tahun 2014. Pada tahun 2004, banyak pimpinan partai politik yang membuat klaim angkat memperoleh sekian persen suara atau sekian persen kursi. Sebetulnyaklaim tersebut dapat dibuktikan dengan uji hipotesis berdasarkan statistik. Akan tetapi, saat itu, lembaga survei politik belum banyak. Tahun 2009, kemampuan statistika dipakai oleh beberapa lembaga survei untuk membuat “quick count” atau hitung cepat dan “exit polls” untuk memperkirakan hasil Pemilu.
Pada saat itu, sejumlah pimpinan partai politik begitu gagap dengan penggunaan sains dalam politik, dalam hal ini matematika atau statistika. Sebagian mengeluarkan pernyataan bahwa survei ini survei bayaran partai lawan atau data direkayasa. Sebagian lain membuat survei yang tidak ilmiah, yang bertujuan menyenangkan pimpinan parpol tapi sama sekali tidak bisa menggambarkan opini publik. Sebagian pemakai internet membuat internet polling di website dan blog.
Posting saya kali ini adalah tentang penjelasan bagaimana suatu survei ilmiah dibuat. Juga ada penjelasan apa itu “quick count” dan “exit polls”. Pada survei ilmiah, harus ada penjelasan mengenai tingkat kepercayaan, batas kesalahan dan jumlah sampel, serta bagaimana caranya survei atau polling dilakukan.
***
Istilah-istilah yang dipakai dalam Pemilu Indonesia dari 2004 hingga 2014:
- Survei (politik) adalah suatu jajak pendapat pada sejumlah orang sebagai untuk memperkirakan opini publik dari suatu populasi. Pada survei ilmiah, pengambilan sampel dari 2000 orang secara acak terkendali bisa menggambarkan opini publik dari populasi 100 juta orang. (wiki tentang survey: en,de,id)
- Survei menjelang pemilihan adalah survei yang dilakukan sebelum pemilihan umum atau pemilihan lain seperti pilkada, pilgub, dll. Survei menjelang pemilihan biasa dilakukan untuk menghitung elektabilitas suatu partai atau orang peserta pemilihan. Dari wiki Pemilu 2014, sejumlah survei ini bisa dilihat hasilnya.
- Hasil penghitungan suara sementara adalah hasil penghitungan suara yang dilakukan KPU dan panitia pemilihan, dari tingkat TPS, kecamatan, kota/kabupaten/provinsi, hingga pusat. Pada tahun 2004 dan 2009, ada IT KPU yang menyajikan hasil penghitungan suara sementara di website. Ini bukan survei dan bukan polling, walau secara matematis bisa saja diperlakukan sebagai suatu survei.
- Quick Count atau Hitung Cepat adalah metode pengambilan sampel dari beberapa tempat pemungutan suara (TPS) untuk memperkirakan hasil Pemilu. Yang menjadi sampel pada quick count adalah hasil TPS, bukan orang. Jadi dari sebagian TPS, misalnya 2000 TPS, kita bisa memprediksi hasil dari seluruh populasi, yaitu 550 ribu TPS atau lebih.
- Exit Polls adalah jajak pendapat dari orang-orang yang telah selesai mencoblos di TPS. Yang menjadi sampel pada exit polls adalah orang. Pada exit polls, selain pertanyaan apa partai yang dipilih, peserta polling juga bisa ditanya mengenai identitasnya (agama, umur, tingkat pendidikan, dll) dan opini mengenai pemilu, seperti apa harapan ke depan, siapa presiden yang akan dipilih, pemilu sebelumnya memilih apa, dll. Dari exit polls, sampel 2000 orang bisa dipakai menggambarkan opini publik dari populasi 100 juta orang.
- Internet Polling adalah pengambilan sampel yang dibuat oleh website atau blog. Ini bukan survei ilmiah karena pengambilan sampel tidak bisa terkendali: apakah satu orang memilih lebih dari satu kali, bagaimana penyebaran geografis peserta polling, dll. Internet polling cukup marak pada Pemilu 2004 dan 2009. Saat itu berdasarkan internet polling, PKS mendapat lebih dari 40% suara.
- SMS Polling adalah pengambilan sampel menggunakan SMS. Ini juga bukan survei ilmiah, dengan alasan yang sama dengan internet polling.
***
Apa itu survei ilmiah? Suatu survei politik itu ilmiah jika pengambilan sampel dilakukan secara acak dan batas-batas yang jelas (terkendali). Acak (random) itu maksudnya tidak ada pola. tiada hubungan kausalitas dan tiada hubungan koherensi (wiki: en,de). Contoh hal-hal yang tidak acak, adalah pengambilan sampel dilakukan hanya pada golongan tertentu atau hanya pada daerah tertentu. Polling di laman internet dan via SMS bisa menyebabkan hal-hal yang tidak acak karena pesertanya bisa saja hanya dari golongan tertentu. Batas yang jelas (terkendali) pada suatu survei yang dimaksud adalah seperti ini
- Berapa jumlah sampelnya? Mengapa?
- Bagaimana cara pengambilan sampel? Mengapa?
- Rentang waktu kapan pengambilan sampel diambil.
- Berapa jumlah sampel di daerah ini dan di daerah itu? Mengapa?
- Berapa jumlah sampel pria dan yang wanita? Mengapa?
Pada pengambilan sampel secara acak sederhana (simple random sampling, wiki: en), kita bisa mengambil sampel sejumlah tertentu misalnya 2000. Lalu kita bisa menghitung rata-rata atau proporsi suara pilihan politik. Pelaku survei tinggal bertanya kepada 2000 orang yang ditemui secara acak. Akan tetapi cara ini menyimpan kelemahan. Indonesia memiliki kondisi geografis tertentu dan penyebaran penduduk khas. Jika metode acak sederhana yang dipakai, penyurvei bisa bertanya secara acak di daerah ini namun lupa bertanya di daerah lain. Akibatnya hasil survei belum tentu menggambarkan opini publik. Cara lain adalah dengan menggunakan pengambilan sampel secara acak berjenjang (stratified random sampling, wiki: en,de). Contoh:
- Pada pengambilan sampel, di provinsi ini sampel diambil sekian dan di tempat lain berbeda, sesuai proporsi jumlah penduduk. Begitu pula proporsi di kota ini dan di kabupaten itu.
- Proporsi kota dan desa juga diperhatikan, misalnya sampel diambil di 60% desa dan 40% kelurahan (di kota) berdasarkan proporsi penduduk.
- Proporsi pria dan wanita juga diperhatikan, misalnya sample pria dan sampel wanita harus sama (50:50).
Dengan metode pengambilan sampel secara acak berjenjang ini, opini publik bisa digambarkan menurut distribusi wilayah, gender, dan geografis.
***
Berapa jumlah sampel yang harus diambil? Jumlah sampel yang diambil itu tergantung seberapa akurat kita ingin memperkirakan seluruh populasi. Prinsipnya ada dua:
- Semakin banyak sampel, semakin akurat
- Semakin banyak sampel, semakin mahal biaya survei
Menurut statistika, jumlah sampel itu tergantung seberapa besar batas kesalahan (margin of error) dan tingkat kepercayaan (confidence level) yang kita tetapkan. Rumusnya ada di bawah.
***
Apa itu batas kesalahan? Batas kesalahan atau margin of error adalah rentang kesalahan pada hasil suatu pengambilan sampel (wiki: en,id). Misalnya pada survei politik, ada tulisan margin of error 2%, sedangkan PDI-P mendapat 19%, Golkar 14%, PKS 5% , dll. Itu artinya PDI-P suaranya bisa meleset plus-minus 2%, sehingga suara PDI-P berkisar 17 hingga 21%. Sedangkan Golkar antara 12 hingga 16%. Lalu PKS antara 3 hingga 7%. Hubungan antara batas kesalahan dengan jumlah sampel akan dijelaskan pada rumus di bawah.
***
Apa itu tingkat kepercayaan dan selang kepercayaan? Tingkat kepercayaan (confidence level) dan selang kepercayaan (confidence interval) saling berhubungan. Hal ini bisa dijelaskan dengan gambar Distribusi Gaussian (dari website National Curve Bank) berikut ini.

Distribusi Gaussian
Pada distribusi normal atau Gaussian, terdapat kurva berbentuk bel seperti pada gambar. Di situ terdapat angka rata-rata yaitu 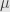
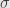
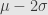

Di sini selang kepercayaan (confidence interval) menunjukkan seberapa jauh hasil sampling boleh menyimpang untuk tetap dipercaya. Tingkat kepercayaan (confidence level) menunjukkan probabilitas atau kemungkinan suatu hasil sampling berada pada selang kepercayaan. Silahkan baca buku probabilistika dan statistika dasar untuk penjelasan yang lebih baik dan kalau malas silahkan baca wiki: en,de,id.
Untuk meningkatkan tingkat kepercayaan, selang kepercayaan harus diperlebar. Berarti hasilnya harus semakin menyimpang dari angka rata-rata, dong? Berarti makin besar saja batas kesalahannya, dong? Ya, betul, akan tetapi jika simpangan
***
Rumus ini, adalah rumus mencari batas kesalahan (margin of error), pada survei.
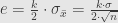
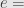

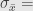


Dari rumus di atas, dapat dicari hubungan antara berapa batas kesalahan yang dimaklumi dan berapa jumlah sampel yang diinginkan. Semakin besar jumlah sampel, maka semakin kecil kesalahannya. Selain itu, tingkat kepercayaan (confidence level) dan selang kepercayaan (confidence interval) berhubungan dengan besarnya 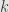
setara dengan selang kepercayaan
dan tingkat kepercayaan 68,26%
setara dengan tingkat kepercayaan 95% dan selang kepercayaan
setara dengan selang kepercayaan
dan tingkat kepercayaan 95,44%
setara dengan tingkat kepercayaan 99% dan selang kepercayaan
setara dengan selang kepercayaan
dan tingkat kepercayaan 99,74%
***
Contoh pertama:
Hasil exit polls dari Center for Strategic and International Studies (CSIS) dan Cyrus Network, 9 April 2014 (dari berita Antara).
Jumlah sampel 8000 orang. Berapa batas kesalahannya (margin of error)?
Jika tingkat kepercayaan 95%, maka selang kepercayaan 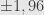
Batas kesalahannya adalah 0,011 = 1,1%.
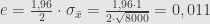
Jika tingkat kepercayaan 99%, maka selang kepercayaan 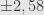
Batas kesalahannya adalah 0,0144 = 1,44%.
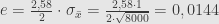
Margin of error yang kecil, tidak lebih dari 1,5%. Lumayan akurat.
***
Contoh kedua:
Hasil quick count dari Jaringan Suara Indonesia (JSI), 9 April 2014 (dari berita KOMPAS).
Jumlah sampel 2000 TPS. Berapa batas kesalahannya (margin of error)?
Jika tingkat kepercayaan 95%, maka selang kepercayaan
Batas kesalahannya adalah 0,022 = 2,2%.
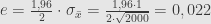
Jika tingkat kepercayaan 99%, maka selang kepercayaan
Batas kesalahannya adalah 0,029 = 2,9%.
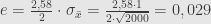
Margin of error di bawah 3%.
***
Contoh ketiga:
Joko ingin membuka usaha survei politik. Dia ingin melakukan survei secara akurat terpercaya. Dia berpikir tingkat kepercayaan 95% dan kalau bisa batas kesalahannya 1% saja. Berapa sampel minimumnya?
Jika tingkat kepercayaan 95%, maka selang kepercayaan
maka

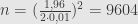
Jadi jumlah sampel yang harus diambil adalah 9604.
Wah, banyak sekali. Joko pun bingung bagaimana menggaji orang buat survei untuk seluruh Indonesia. Biaya perjalanan mereka juga besar. Joko pun berpikir bagaimana kalau batas kesalahannya jadi 3% saja, jadi jumlah sampel cukup 2000 saja.
***
Begitulah hubungan antara jumlah sampel dan batas kesalahan (margin of error) pada suatu survei ilmiah. Jadi pada survei menjelang Pemilu, “exit polls” maupun “quick count”, kita sebagai pembaca atau penonton berita harus kritis dengan bertanya berapa jumlah sampel, batas kesalahan, dan tingkat kepercayaan. Tentu saja kita harus kritis untuk mengetahui bagaimana juga survei dilakukan, misalnya stratified random sampling (acak berjenjang) atau tidak. Kapan survei dilakukan juga perlu diketahui.
Nah, kalau ada pimpinan partai yang membuat klaim partainya akan memperoleh sekian suara atau sekian kursi, akan tetapi hasil beberapa survei ilmiah tidak menunjukkan hasil sesuai kata-kata pimpinan parpol, itu artinya orang ini tidak memiliki argumentasi ilmiah.
Begitu pula, jika ada organisasi jadi-jadian yang biasanya dibentuk oleh suatu partai politik, membuat suatu survei. Akan tetapi dia tidak mencantumkan jumlah sampel, batas kesalahan (margin of error), tingkat kepercayaan, serta bagaimana dan kapan survei diadakan. Itu artinya survei ini ngawur atau tidak ilmiah.
Kalau ada orang yang bilang survei ini rekayasa parpol atau survei itu survei bayaran, kita juga harus kritis. Sekarang ada 56 lembaga survei yang tercatat oleh KPU. Jadi lihat-lihat saja hasil survei dari 56 lembaga tersebut kemudian bandingkan. Serta di wikipedia juga sudah ada yang merangkum survei-survei yang telah dilakukan selama ini. Jangan hanya karena kita tidak suka dengan hasil suatu survei, kita menganggap survei ini ngawur.
Ada 56 lembaga survei untuk Pemilu. http://t.co/c0Ad8GBLvP
— iscab.saptocondro (@saptocondro) April 2, 2014
***
Posting ini adalah posting tentang penggunaan statistika dalam dunia politik. Posting serupa dalam dunia perjodohan, bisa dibaca pada “Semua pria sama saja“.
Oldenburg, 9 April 2014
Semua pria sama saja, menurut probabilitas dan statistika
Ada pernyataan yang sering dikeluarkan oleh orang-orang yang kecewa.
- “Ah, semua laki-laki sama saja. Brengsek!”
- “Ah, semua wanita sama saja. Matré!”
- dan lain-lain
Pernyataan di atas adalah suatu premis logis yang bisa dinegasikan dan dihubungkan dengan premis lain untuk membangun silogisme.
Negasi dari “semua pria sama saja” adalah “Ada pria yang tidak sama”.
Aku bertanya-tanya mengenai kebenaran dari pernyataan “semua pria sama saja”, bukan hanya secara logis, melainkan juga matematis. Ada cara untuk mengetahui kebenaran pernyataan ini secara matematis, yaitu dari ilmu probabilitas dan statistika.
Untuk menguji kebenaran pernyataan “semua pria sama saja, Brengsek!” maka perlu suatu survei atau pengambilan sampel, dari populasi pria. Berapa sampel yang diperlukan? Bagaimana tingkat kepercayaannya? Bagaimana galatnya?
***
Rumus ini, adalah rumus mencari batas kesalahan (margin of error), pada survei.
Dari rumus di atas, dapat dicari hubungan antara berapa batas kesalahan yang dimaklumi dan berapa jumlah sampel yang diinginkan. Semakin besar jumlah sampel, maka semakin kecil kesalahannya.
Selain itu, tingkat kepercayaan (confidence level) dan selang kepercayaan (confidence interval) berhubungan dengan besarnya
Gambar dari National Curve Bank berikut menjelaskan hubungan tingkat/selang kepercayaan dalam distribusi Gaussian.
Distribusi Gaussian
Tingkat kepercayaan 95% berarti jika survei dilakukan 100 kali, maka 95 survei menunjukkan hasil yang sama dan 5 yang berbeda.
Batas kesalahan 1% berarti pada suatu survei, ada 1% sampel yang menyimpang.
Makna tingkat kepercayaan dan batas kesalahan di atas tidak terlalu tepat karena hanya dipakai untuk mempermudah penjelasan.
***
Kembali ke pernyataan “Semua laki-laki itu sama aja, brengsek.”
Untuk memperoleh tingkat kepercayaan 95% dengan batas kesalahan 1%, hitung-hitungannya begini.
Tingkat kepercayaan 95% berarti 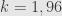
Simpangan baku setelah distandardisasi/dinormalisasi selalu satu.
maka

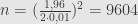
Jadi untuk tingkat kepercayaan 95% dan batas kesalahan 1%, perlu melakukan pengambilan sampel acak sejumlah 9604 pria, untuk membuktikan kebenaran pernyataan “Semua pria itu brengsek.”
Oh, ya, kalau tingkat kepercayaannya dinaikkan menjadi 99% dan batas kesalahan tetap 1%, maka

Maka sampel yang perlu diambil secara acak adalah 16641 pria.
***
Jika kamu kecewa dengan pasanganmu, jangan bilang “Ah, semua pria sama aja, suka berbohong!” atau “Ah, semua wanita sama aja, matre semua!” sebelum merasakan pacaran sebanyak 16000 kali dan membuktikan pernyataan tersebut.
Bremen, 18 Juli 2013
Mengapa Kartini dan bukan yang lainnya? Simple Complexity Analysis
Minggu lalu, dunia online dialiri tulisan tentang mengapa Kartini harus dirayakan setiap 21 April dan mengapa ia menjadi mitos. Ada dua artikel lama yang dikopi-paste ke milis-milis dan juga foto-foto Facebook, serta ditautkan ke Twitter:
- “Mitos Kartini dan Rekayasa Sejarah“, 2009, Adian Husaini, Jurnal Islamia, INSISTS-Republika
- “Mengapa Harus Kartini?“, 2009, Tiar Anwar Bachtiar, Jurnal Islamia, INSISTS-Republika
Kedua tulisan tersebut merujuk pada artikel Harsja W. Bahtiar “Kartini dan Peranan Wanita dalam Masyarakat Kita”, di buku Satu Abad Kartini (1879-1979), (Jakarta: Pustaka Sinar Harapan, 1990, cetakan ke-4).
Pada ketiga artikel di atas, terdapat kritik terhadap pengkultusan Kartini. Selain itu, ada pertanyaan mengapa Kartini diperingati harinya setiap 21 April. Baik negara maupun masyarakat, merayakan Kartini namun tidak merayakan tokoh wanita lainnya, seperti Dewi Sartika, Rasuna Said, Rohana Kudus, Cut Nyak Dien, Laksamana Kemalahayati, dll. Sebagian tokoh wanita yang disebut T.A. Bachtiar, mengangkat senjata berperang melawan Belanda. Sebagian lain tidak menggunakan kekerasan, namun mendirikan sekolah perempuan, atau minimal lembaga kursus. Kritik berlanjut menjadi, mengapa hanya Kartini dan bukan yang lainnya.
Tulisanku tidak akan membahas mengenai aspek historis mengenai ketokohan Kartini dan perayaannya. Kali ini, aku akan membahas fenomena kompleksitas (wiki: en,de,en). Aku tidak akan memihak Kartini maupun tokoh wanita yang lainnya. Aku akan menggambarkan suatu model matematis yang menjelaskan mengapa Kartini digemari.
***
Pada suatu diskusi di Bremen, kawanku menyodorkan suatu paper tentang kompleksitas. Sayang sekali, paper ini entah kutaruh di mana. Kami mendiskusikan paper tersebut yang berisi suatu model yang menjelaskan mengapa motor bakar (combustion engine) berkembang lebih pesat daripada motor listrik (electric engine). Juga mengapa masyarakat di suatu tempat, memilih cara hidup yang ini, bukan yang lainnya. Mengapa warga suatu daerah memilih beternak bebek daripada kambing walau kedua hewan memiliki kemampuan yang sama untuk hidup dan sintas di tempat itu. Topik doktoral kawan-kawanku adalah tentang fenomena sosio-ekologi yang berhubungan dengan laut, karang, ikan, nelayan, dst. di suatu daerah di Sulawesi. Aku ikut diskusi dalam rangka makan-gak-makan-asal-kumpul, bukan untuk kegiatan akademik.
Modelnya seperti ini. Dimisalkan pada suatu kotak terdapat 1 bola hitam dan 1 bola putih. Satu bola diambil secara acak (random). Jika bola hitam terambil, maka bola hitam harus dikembalikan ke dalam kotak dan ada satu bola hitam yang ditambahkan ke dalam kotak. Jadi kotak menjadi memiliki 2 bola hitam dan 1 bola putih. Begitu juga sebaliknya, jika bola putih yang terambil. Pengambilan yang sederhana ini, jika dilakukan berulang (iterasi), akan menghasilkan fenomena kompleksitas.
Menurut diskusi Bremen, bola mana yang terambil terlebih dahulu akan lebih diuntungkan. Sistem ini sangat tergantung keadaan awal (initial condition). Penjelasan matematisnya terdapat di paper yang hilang jejaknya tersebut. Kini aku akan merekonstruksi modelnya secara lebih sederhana dengan contoh.
***
Keadaan awal: Dalam kotak, 1 bola hitam + 1 bola putih
Kemungkinan bola hitam terambil acak adalah 
Langkah ke-1: bola hitam kebetulan terambil. Maka harus ada bola hitam yang ditambahkan. Jadinya 2 bola hitam dan 1 bola putih.
Kemungkinan bola hitam terambil acak pada langkah ini adalah 
Kemungkinan langkah ini terus menghasilkan bola hitam:


Langkah ke-2: bola hitam kebetulan terambil lagi. Isi kotak jadi 3 bola hitam dan 1 bola putih.
Kemungkinan bola hitam terambil acak pada langkah ini adalah 
Kemungkinan langkah ini terus menghasilkan bola hitam:


Dan seterusnya, hingga langkah ke-k: Isi kotak jadi 
Kemungkinan bola hitam terambil terus:
Begitu pula, jika bola putih yang terambil terus: Isi kotak 1 bola hitam + 


Pertanyaan selanjutnya adalah:
- Bagaimana kalau pada suatu langkah, bola hitam dan bola putih terambil bergantian, dengan urutan acak?
- Bagaimana kalau kondisi awalnya tidak seimbang? Bagaimana kalau jumlah bola putih dan bola hitam yang asimetris?
***
Pada contoh lain. Kondisi awal bersifat asimetris. Ini lebih menggambarkan kejadian di dunia nyata yang berisi distribusi yang timpang, contoh kesenjangan sosial, social sentiment, tradisi, dll.
Kondisi awal: 7 bola hitam + 3 bola putih.
Kemungkinan bola hitam terambil acak adalah 

Alternatif I: Bola hitam terambil terus
Langkah ke-1: Isi kotak jadi 8 bola hitam dan 3 bola putih.
Kemungkinan bola hitam terambil acak pada langkah ini adalah 
Kemungkinan langkah ini terus menghasilkan bola hitam:


Langkah ke-2: Isi kotak jadi 9 bola hitam dan 3 bola putih.
Kemungkinan bola hitam terambil acak pada langkah ini adalah 
Kemungkinan langkah ini terus menghasilkan bola hitam:


Dan seterusnya, hingga langkah ke-k: Isi kotak menjadi 
Pada


Alternatif II: Bola putih terambil terus
Langkah ke-1: Isi kotak jadi 7 bola hitam dan 4 bola putih.
Kemungkinan bola hitam terambil acak pada langkah ini adalah 
Kemungkinan langkah ini terus menghasilkan bola putih:


Langkah ke-2: Isi kotak jadi 7 bola hitam dan 5 bola putih.
Kemungkinan bola hitam terambil acak pada langkah ini adalah 
Kemungkinan langkah ini terus menghasilkan bola putih:


Dan seterusnya, hingga langkah ke-k: Isi kotak menjadi 7 bola hitam dan 
Pada


Dari kedua alternatif di atas, tampak bahwa pada bola hitam lebih diuntungkan daripada bola putih.
dengan A dan B konstanta, pada langkah ke-k, ketika

Alternatif III: Bola hitam dan bola putih terambil bergantian dengan urutan acak
Untuk alternatif ini, bisa kembali lagi dianalisis seperti alternatif I atau II. Iterasi ini sebetulnya lebih mudah dilakukan komputer daripada manusia.
***
Dari beberapa contoh di atas, tampak bahwa kondisi saat ini tergantung kondisi sebelumnya. Keadaan awal yang timpang, bisa menghasilkan kesempatan yang asimetris. Ada pihak yang diuntungkan dari kesenjangan ini, dan dirugikan karena kurangnya kesempatan.
Contoh di atas adalah untuk dua pilihan. Untuk multi pilihan bisa juga berlaku pemodelan yang sama. Bisa lihat sebagai berikut.
- Kartini memiliki 17 bola hijau
- Dewi Sartika memiliki 9 bola kuning
- Cut Nyak Dien memiliki 5 bola kelabu
- Rasuna Said memiliki 3 bola merah muda (pink)
- Martha Christina Tiahahu memiliki 2 biru
Total bola adalah 36.
Ketika iterasi dilakukan sebanyak
- Kartini berpeluang
(peluang terbesar)
- Dewi Sartika berpeluang
- Cut Nyak Dien berpeluang
- Rasuna Said berpeluang
- Martha Christina Tiahahu berpeluang
(peluang terkecil)



Dengan A, B, C, D, dan E adalah konstanta.
Kartini terpilih karena ia lebih dahulu diminati daripada tokoh wanita lainnya. Seiring berjalannya waktu, ia dirayakan terus-menerus. Ini membentuk tradisi untuk semakin menambah minat akan Kartini. Ini terjadi ketika isi kotak tidak dipengaruhi agen dari luar sistem yang menambah bola, tanpa mengikuti aturan.
Jika ada suatu agen dari luar sistem yang menambah bola, isi kotak bisa berubah keadaan. Keadaan selanjutnya akan tergantung keadaan awal. Jika ada revolusi, yang menghapus Kartini dalam sejarah atau mengganti perayaan Kartini dengan tokoh lain, bisa saja keadaan selanjutnya berubah.
Bremen, 26 April 2013
Lotto Jerman: Analisis Probabilitas Kemenangan
Di Jerman, ada lotere yang dimiliki negara, namanya Lotto. Setiap hari Rabu dan Sabtu, di televisi nasional milik negara (ARD atau ZDF), ditampilkan pengambilan undian lotere ini. Pada Lotto, setiap orang membeli kupon, baik berupa kertas di kios maupun secara online pada website.
Setiap pemain lotere memiliki kebebasan memilih 6 angka dari 49 angka. Selain itu, pada kupon terdapat nomor kupon. Kemenangan seorang pemain tergantung dari angka yang dipilih bebas dan angka kupon. Setiap membeli undian, ada biaya 0,75 EUR untuk 1 pilihan. Ditambah biaya administrasi, per lembar kupon.
Pada pengundian, terdapat 49 bola yang memiliki nomor 1 hingga 49. Lalu diputar-putarlah bola-bola tersebut. Kemudian diambillah 7 bola secara acak: 6 angka utama dan 1 angka substitusi (Zusatzzahl). Selain itu, ada pengundian Superzahl, yaitu angka terakhir pada nomor kupon. Sepuluh bola, dari angka 0 hingga 9, diundi secara acak untuk diambil 1.
Jadi ada dua pengundian independen yang menyebabkan
- 49 angka (lotere) = 6 angka benar+ 1 angka pengganti (Zusatzzahl) + 42 angka salah
- 10 angka (kupon) = 1 angka Superzahl + 9 angka salah
***
Kemungkinan yang muncul dari pengundian tersebut, sebagai berikut
- Dari 49 diambil 6:
- Dari 10 diambil 1:
- Perkalian keduanya:
- Jadi hampir 140 juta kemungkinan pengundian



Cara menghitungnya menggunakan Kombinasi (wiki: id,en,de):


***
Pada LOTTO, terdapat beberapa level kemenangan (Gewinnklasse):
- Klasse I : 6 angka benar + 1 Superzahl
- Klasse II: 6 angka benar
- Klasse III: 5 angka benar + 1 Zusatzzahl
- Klasse IV: 5 angka benar
- Klasse V: 4 angka benar + 1 Zusatzzahl
- Klasse VI: 4 angka benar
- Klasse VII: 3 angka benar + 1 Zusatzzahl
- Klasse VIII: 3 angka benar
Setengah uang yang dikumpulkan LOTTO diambil bandar, yaitu negara, untuk kegiatan kesenian, olahraga, dll serta tentu saja administrasi dan bagi hasil dengan kios. Jadi bandar dan kios takkan terkena resiko kerugian dari sistem perjudian ini. Setengah lagi, diberikan kepada para pemenang undian. Uang yang diundi dibagi dengan kuota sesuai level/kelas di atas, sebagai berikut.
- 10% untuk Klasse 1
- 8% untuk Klasse 2
- 5% untuk Klasse 3
- 13% untuk Klasse 4
- 2% untuk Klasse 5
- 10% untuk Klasse 6
- 8% untuk Klasse 7
- 44% untuk Klasse 8
Jika pada suatu kelas, tidak ada pemenang, maka hadiah akan diakumulasi pada pengundian berikutnya untuk kelas/level yang sama. Hal ini yang disebut Jackpot.
***
Analisis probabilitas untuk tiap level kemenangan bisa dilihat di bawah ini.
Klasse I: 6 angka benar + 1 Superzahl
- Dari 6 angka benar diambil 6:
- Dari 1 angka Zusatzzahl diambil 0:
- Dari 42 angka salah diambil 0:
- Dari 1 angka Superzahl diambil 1:
- Dari 9 angka salah diambil 0:
- Perkalian semuanya:
- Rasio kemenangan:
- Secara ekonomis, perjudian ini menguntungkan jika hadiahnya
EUR
- Jadi kalau hadiahnya di bawah 105 juta EUR untuk Klasse I, sebetulnya Anda membuang uang.







Klasse II: 6 angka benar (+ 0 Superzahl)
- Dari 6 angka benar diambil 6:
- Dari 1 angka Zusatzzahl diambil 0:
- Dari 42 angka salah diambil 0:
- Dari 1 angka Superzahl diambil 0:
- Dari 9 angka salah diambil 1:
- Perkalian semuanya:
- Rasio kemenangan:
- Secara ekonomis, perjudian ini menguntungkan jika hadiahnya
EUR
- Jadi kalau hadiahnya di bawah 12 juta EUR untuk Klasse II, sebetulnya Anda membuang uang.



Klasse III: 5 angka benar + 1 Zuzatzzahl
- Dari 6 angka benar diambil 5:
- Dari 1 angka Zusatzzahl diambil 1:
- Dari 42 angka salah diambil 0:
- Dari 10 angka kupon diambil 1:
- Perkalian semuanya:
- Rasio kemenangan:
- Secara ekonomis, perjudian ini menguntungkan jika hadiahnya
EUR
- Jadi kalau hadiahnya di bawah 1,75 juta EUR untuk Klasse III, sebetulnya Anda membuang uang.




Klasse IV: 5 angka benar (+ 1 angka salah)
- Dari 6 angka benar diambil 5:
- Dari 1 angka Zusatzzahl diambil 0:
- Dari 42 angka salah diambil 1:
- Dari 10 angka kupon diambil 1:
- Perkalian semuanya:
- Rasio kemenangan:
- Secara ekonomis, perjudian ini menguntungkan jika hadiahnya
EUR
- Jadi kalau hadiahnya di bawah 42 ribu EUR untuk Klasse IV, sebetulnya Anda membuang uang.



Klasse V: 4 angka benar + 1 Zuzatzzahl (+ 1 angka salah)
- Dari 6 angka benar diambil 4:
- Dari 1 angka Zusatzzahl diambil 1:
- Dari 42 angka salah diambil 1:
- Dari 10 angka kupon diambil 1:
- Perkalian semuanya:
- Rasio kemenangan:
- Secara ekonomis, perjudian ini menguntungkan jika hadiahnya
EUR
- Jadi kalau hadiahnya di bawah 17 ribu EUR untuk Klasse V, sebetulnya Anda membuang uang.



Klasse VI: 4 angka benar (+ 2 angka salah)
- Dari 6 angka benar diambil 4:
- Dari 1 angka Zusatzzahl diambil 0:
- Dari 42 angka salah diambil 2:
- Dari 10 angka kupon diambil 1:
- Perkalian semuanya:
- Rasio kemenangan:
- Secara ekonomis, perjudian ini menguntungkan jika hadiahnya
EUR
- Jadi kalau hadiahnya di bawah 813 EUR untuk Klasse VI, sebetulnya Anda membuang uang.



Klasse VII: 3 angka benar + 1 Zuzatzzahl (+ 2 angka salah)
- Dari 6 angka benar diambil 3:
- Dari 1 angka Zusatzzahl diambil 1:
- Dari 42 angka salah diambil 2:
- Dari 10 angka kupon diambil 1:
- Perkalian semuanya:
- Rasio kemenangan:
- Secara ekonomis, perjudian ini menguntungkan jika hadiahnya
EUR
- Jadi kalau hadiahnya di bawah 610 EUR untuk Klasse VII, sebetulnya Anda membuang uang.



Klasse VIII: 3 angka benar (+ 3 angka salah)
- Dari 6 angka benar diambil 3:
- Dari 1 angka Zusatzzahl diambil 0:
- Dari 42 angka salah diambil 3:
- Dari 10 angka kupon diambil 1:
- Perkalian semuanya:
- Rasio kemenangan:
- Secara ekonomis, perjudian ini menguntungkan jika hadiahnya
EUR
- Jadi kalau hadiahnya di bawah 46 EUR untuk Klasse VIII, sebetulnya Anda membuang uang.



***
Selama ini, hadiah dari LOTTO selalu di bawah angka harapan matematis (Expected value/Erwartungswert). Dari kelas I hingga VIII, hadiahnya tak pernah menguntungkan, secara statistik, seperti perhitungan di atas. Jadi membeli LOTTO adalah cara membuang uang, untuk disumbangkan kepada kegiatan olahraga dan kesenian (kalau berpikir positif). Janganlah berjudi hingga kecanduan, seperti pesan pada kupon LOTTO (dan websitenya).
Bremen, 11 April 2013
Information transfer rate (ITR) and Poco-poco dance
Information transfer rate (
with 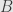


Speed/rate (
with 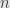

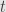

Bits per transfer (
with


Accuracy (

***
First Example:
I am learning how to dance. The basic steps are just go to left and right. The dance instructor will tell “left” and “right”.
One example is “left, left, right, left, right, right, left, right” That are first eight step of line dance.
In this case, the information type is just LEFT and RIGHT.

In 15 minutes, the instructor has just taught me a dance routine. There was 100 steps. Fiuh, I am sweating. Because I am a beginner, I made 60 mistakes and 40 good dance.



The Accuracy (

The learning speed (

The bits per learning (



The information transfer rate
So I am learning how to dance with a rate of 0.2 bits per minute.

***
Second Example:
Now, I learn how to dance Poco-poco. This line dance comes from North Sulawesi in Indonesia.
The basic steps are
- move left
- move right
- move forward
- move backward
- lean forward
- lean backward
- twist left
- twist right
So the number of information types are

More advanced steps are
- cross forward right
- cross forward left
- cross backward right
- cross backward left
- and so on
So
You can learn the basic step of Poco-poco from here.
***
Third Example:
Well, in a brain-computer interface experiment, a human subject has to do a task containing commands: LEFT, RIGHT, UP, DOWN. So 
***
Well, I am still looking for books about this bits per transfer equation. It has something to do with information entropy.
Bits per transfer (
From wikipedia, the binary entropy function (
with 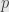

From wikipedia, the Shannon entropy function (
with 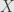

and 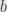

Entropy is a measure of uncertainty associated to random variable. Shannon entropy quantifies expected value of information contained in a message. In binary process, it is quantified in bits.

Other reference:
- J.R. Wolpaw, N. Birbaumer, D.J. McFarland, G. Pfurtscheller, and T.M Vaughan, “Brain-computer interfaces for communication and control,” Clinical Neurophysiology, vol. 113, pp. 767-791, 2002.
- M. Cheng, X. Gao, S. Gao, and D. Xu, “Design and Implementation of a Brain-Computer Interface with High Transfer Rate,” IEEE Transactions on Biomedical Engineering, vol. 49, pp. 1181-1186, October 2002.
- Atmawan-Bisawarna,I.S.C., “Improvement of Response Times in SSVEP-based Brain-Computer Interface,” Master thesis, Information and Automation Engineering, University of Bremen, 2010.
Nürnberg, 17 Maret 2012
Ignatius Sapto Condro Atmawan Bisawarna (iscab)
rank
twiscab
 Darah Juang, Dr. Dro!
Darah Juang, Dr. Dro!- An error has occurred; the feed is probably down. Try again later.
- Brain Robot Research
- EEG electrode placement summary, April 2015
- Bandung Brain-Computer Interface on Indonesia Morning Show, Net TV, June 2014
- EEG electrode placement summary, August 2014
- Bandung Brain Computer Interface: Bionic Arm 2014
- CMS and DRL
- How seriously is Indonesia doing research on Brain-Computer Interface?
- SSVEP electrode position, on my head
- Ethical Questions on Brain Computer Interface, by Paul Root Wolpe
- Bandung Brain Computer Interface
- Standard 10-20 system EEG & me
- The Church of Robotics
- technologeek gaptek
- info beasiswa / scholarship
- An error has occurred; the feed is probably down. Try again later.
- info lowongan kerja / job vacancy
- An error has occurred; the feed is probably down. Try again later.
Badge

social badge



Recent Comments
- iscab.saptocondro
- iscablr
- Senja di Kanal Wolfsburg
- Ketika kita siap BERAKtivitas. Lalu ada kehendak usus besar,...
- Internet 5G ala kampung di Jerman. kbps bukan Mbps. Di...
- Volkswagen di hari Minggu. Volkswagen on a Sunday. Volkswagen...
- Web 1.0, Web 2.0, Web 3.0 Jejaring punya versi #web #123...
- Kuliah yang rajin dan tekun kalau sudah diterima di perguruan...
- 2 Belimbing Malaysia seharga 5 EUR total. #belimbing #malaysia...
- Suasana matahari terbenam di musim semi. Sunset in Spring....
- Sahara Sand & Sunset Scattering Pasir dari Sahara &...
- Nasi Anonim, karena belum sempat memberi nama untuk makanan...
- miliscab
- An error has occurred; the feed is probably down. Try again later.
